

Overview
This was my undergraduate senior design (capstone project). I worked with a colleague to design a hardware-optimised version of k-means clustering for image segmentation. The hardware optimisations include:
- Introducing a grid-based cluster initialisation scheme.
- Eliminating integer division operations.
- Implementing a kd-tree for efficient data assignment to clusters.
We implemented the hardware circuit as verilog and validated its operation in simulation. The circuit takes in a an image and computes clusters from the image pixels. It then builds the segmented version of the image using the computed clusters. The topic areas that this project covers include unsupervised machine learning, digital system design, and algorithmic optimisation. The report follows a specific structure and format based on the submission requirements for the course.
Backstory
COE 405 Project: SIMD architecture for K-Means Clustering

This senior project is a continuation and alternative approach to a project that me and my colleague, Ahmad Alharbi, did for a previous course — COE 405: Design and Modeling of Digital Systems. The project requirement for that course was to implement k-means clustering using verilog. The course instructor at the time, Prof Muhammad Elrabaa, had put up bonus grades for the group who could implement the fastest design as well as the group who could implement the smallest design in terms of resource utilisation. Me and Ahmad decided we wanted to win the fastest design points, so we did a bit more work on developing a high-throughput architecture rather than just implementing a design that works. You can view the project report by clicking on the cover page to the left of this text.
The main idea behind our design was to exploit the parallelism of FPGAs by implementing a Single-Instruction Multiple-Data (SIMD) architecture for clustering, similar to how GPUs operate. SIMD architectures exploit workloads where the same singular operations need to be performed on large volumes of data. Therefore, we can duplicate hardware blocks and string them in parallel so that they are synchronised to perform the same set of operations on different chunks of the dataset at the same time. This is ideal for image processing or machine learning applications where we have large datasets which must be fed into a set of consecutive tasks that operate on singular instances of data (or pixels in the case of images).
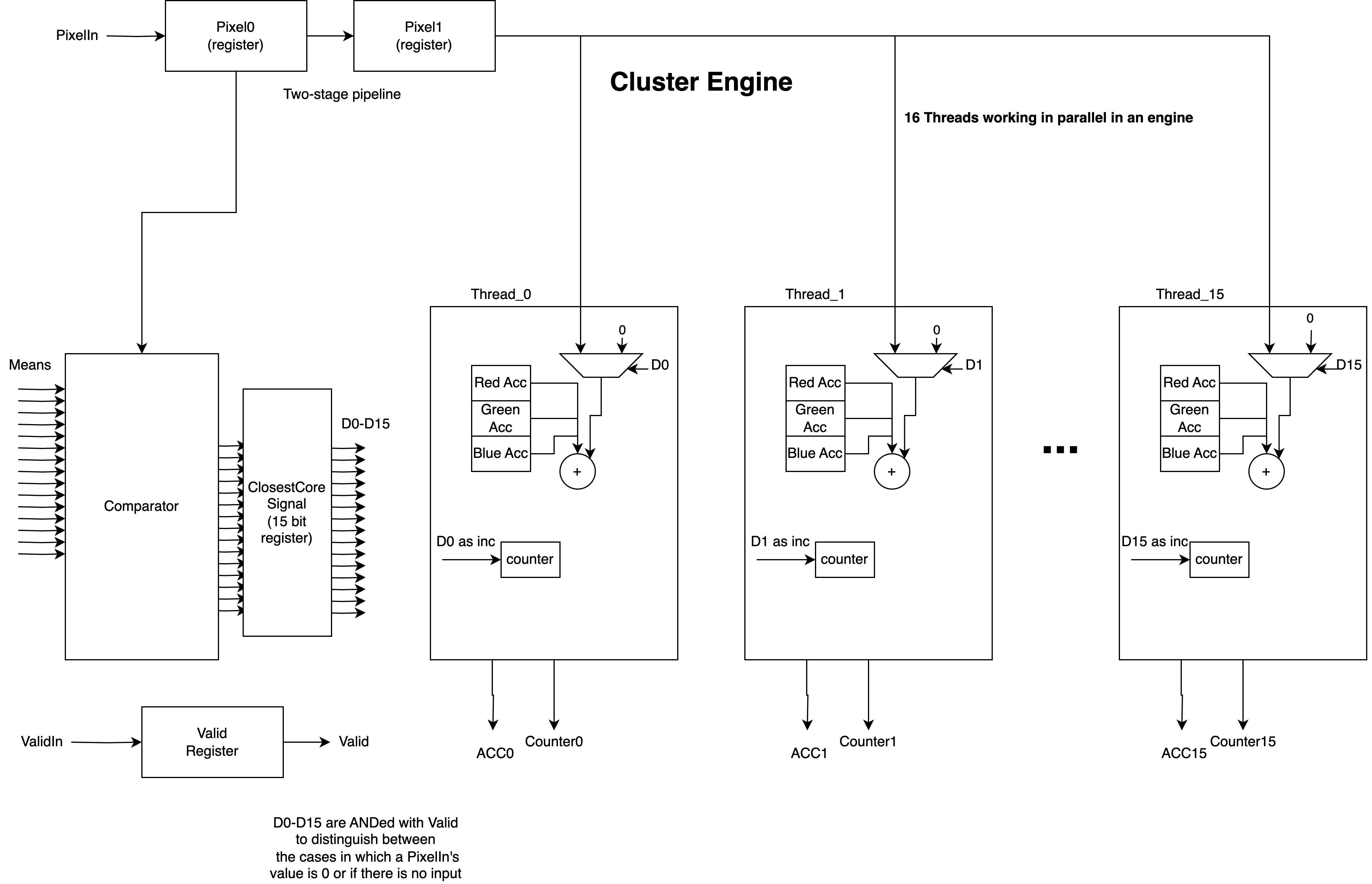
Our resulting design consists of a series of clustering engines with k thread blocks within each engine, in addition to a comparator for pixel assignment to threads. Each thread contains three accumulators corresponding to the RGB components, and a counter corresponing to the number of assigned pixels to the thread. On the outer level, we have BEngines which contain two cluster engines and a dual port memory. More BEngines corresponds to higher levels of parallelism within the overall architecture. We aggregate the cluster engine accumulators and counters to get the individual cluster pixel counters and sums. In the final stage, we divide the cluster sums by the counters to get the mean values of the cluster centroids.
For this project we did not have the base sequential design to compare against, but instead we reported on the number of cycles spent processing and showed that this was usually less than 2600 for K = 4, 8, 12, 16 using 10 cluster engines. On the Cyclone V, the simulator reported a cycle time of 11.471 ns which gives us a total processing time of 29 μs for K = 16.
We won the fastest design award among our course group. Our success in this project motivated us to work on it further for our senior design project in the following semester.
Senior Design Project Clustering Machine
We took a two-stage approach going into the senior project, with the aim of designing a clustering machine architecture based on a more fundamentally efficient and hardware-friendly algorithm. As opposed to the prior course project, here we focused on developing a compact design that can maintain high throughput whilst not consuming as much power during operation. The first stage is algorithmic exploration and optimisation, and the second is implementation of the hardware design. We spent the majority of the period allocated to the design project on the first stage, and a condensed intense finalisation period for the second stage. We came up with three main improvements to the algorithm to improve throughput, which I outline below.
Improvement 1 — Centroid initialisation
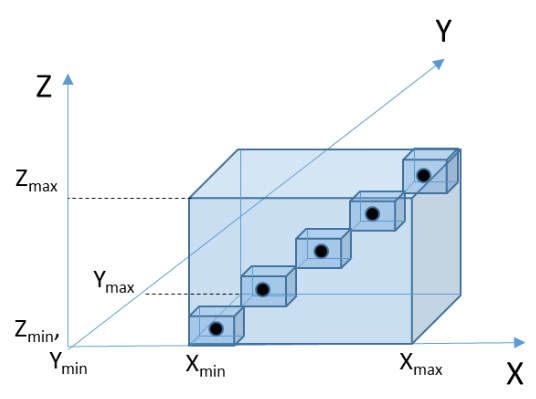
An important component to look into when improving the clustering algorithm is the initialisation strategy for the cluster centroids. Having a good starting point for the algorithm makes reaching convergence easier, since the initial state becomes closer to the final solution. A random or ad-hoc initialisation strategy it not optimal since it would not provide sufficient dispersion of the clusters to cover the solution space. We investigated implemented two different initialisation strategies: diagonal initialisation, and sub-box initialisation. For both of these strategies we made sure to restrict the initial centroid positions within the range of the data across the data dimensions.
Diagonal initialisation
In diagonal initialistion we place the initial centroid positions along the main diagonal of the allowable range of the data, across the three dimensions. Figure 2 shows this approach. It is a reasonable improvement over random initialisation since the initial clusters are evenly distributed over the range of the data, leading to the clusters having more coverage over the range of the data. It is also especially effective when the data is near the main diagonal, which may often be the case. However, the issue with it is that it does not sufficiently cover the space of the data which leads to slower convergence since the cluster centroids must travel farther distances to reach a stable solution.
Sub-box initialisation
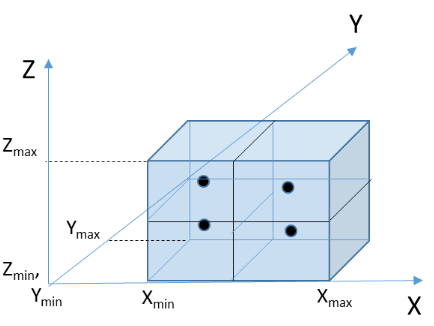
To tackle the space coverage issue associated with diagonal initialisation, we proposed a sub-box initialisation strategy. Here we split the 3D cube encompassing the data into k smaller cubes with a cluster centroid within each. Figure 3 shows how the space is split using this strategy. We can see that using this method, the initial cluster positions cover a wider area of the data space which leads to greater coverage of the possible locations of data points. Compared to diagonal initialisation it significantly reduces any necessary movement of centroids, leading to faster convergence for datasets that have higher levels of dispersion. This is a desirable characteristic for hardware implementations which need to be power-efficient, since the number of operations that are executed to convergence reduces.
However, there is a new issue that is introduced with this increased level of dispersion. Since the clusters are more dispersed across the data range, depending on the dataset, if certain centroids are too far away from the data, it may be the case that no data points will be assigned to them. If this occurs, then the centroid does not move at all from its initial position, rendering it redundant. This usually occurs when the dataset does not follow a cubic evenly-dispersed shape across the data domain, causing some areas to be empty of data points. The centroids that are initialised in those areas will not have any points assigned to them, reducing the clustering quality for a given fixed value of k. Therefore, more work needs to be done on initialisation to ensure that the clusters can be placed within the data distribution of the points, rather than assuming that the distribution follows a cubic shape.
Clustering on independant dimensions

One of the features we experimented with was to perform clustering on each individual dimension independantly, rather than to cluster on the three dimensional data. In essence, this is equivalent to doing a seperate clustering operation for each dimension and reconstructring the cluster centers from the available k values in each dimension. The cluster values on each dimension would be organised into binary trees.
The main advantage of this approach is that it is highly parallelisable due to the independance between dimensions. It can also easily be scaled to an arbitrary number of dimensions. The clustering algorithm also converges much faster since the optimisation is done on a single dimension. However, what we found is that this approach does not meet sufficient accuracy requirements based on the silhouette coefficient metric.
Figure 4 shows the clustering quality from this approach. The silhouette coefficient — which measures how closely packed and distinct the resulting clusters are, came out to be 0.222 for the segmented image in Figure 4. This implies that the clusters are not very well formed and that the clustering quality has degraded significantly for the large gain in performance. Therefore, we had to abandon this approach and look for alternative improvements.